How CustomGPT.ai agents defend against prompt injection and hallucinations
This guide explains how CustomGPT.ai agents are designed to protect against prompt injection and hallucinations. It also outlines the settings you can control to further minimize risks and ensure accurate, secure responses.
Built-in protections
CustomGPT.ai includes several proprietary safeguards to defend against prompt injection and reduce hallucinations by default. These are built into the platform's core agent behavior and do not require any special configuration to start benefiting from them.
Recommended settings for the strongest defense are enabled by default
The most important for agent security are two settings which are available on all plans and enabled by default:
- Anti-Hallucination
Location: Go to your agent’s Personalize > Security tab
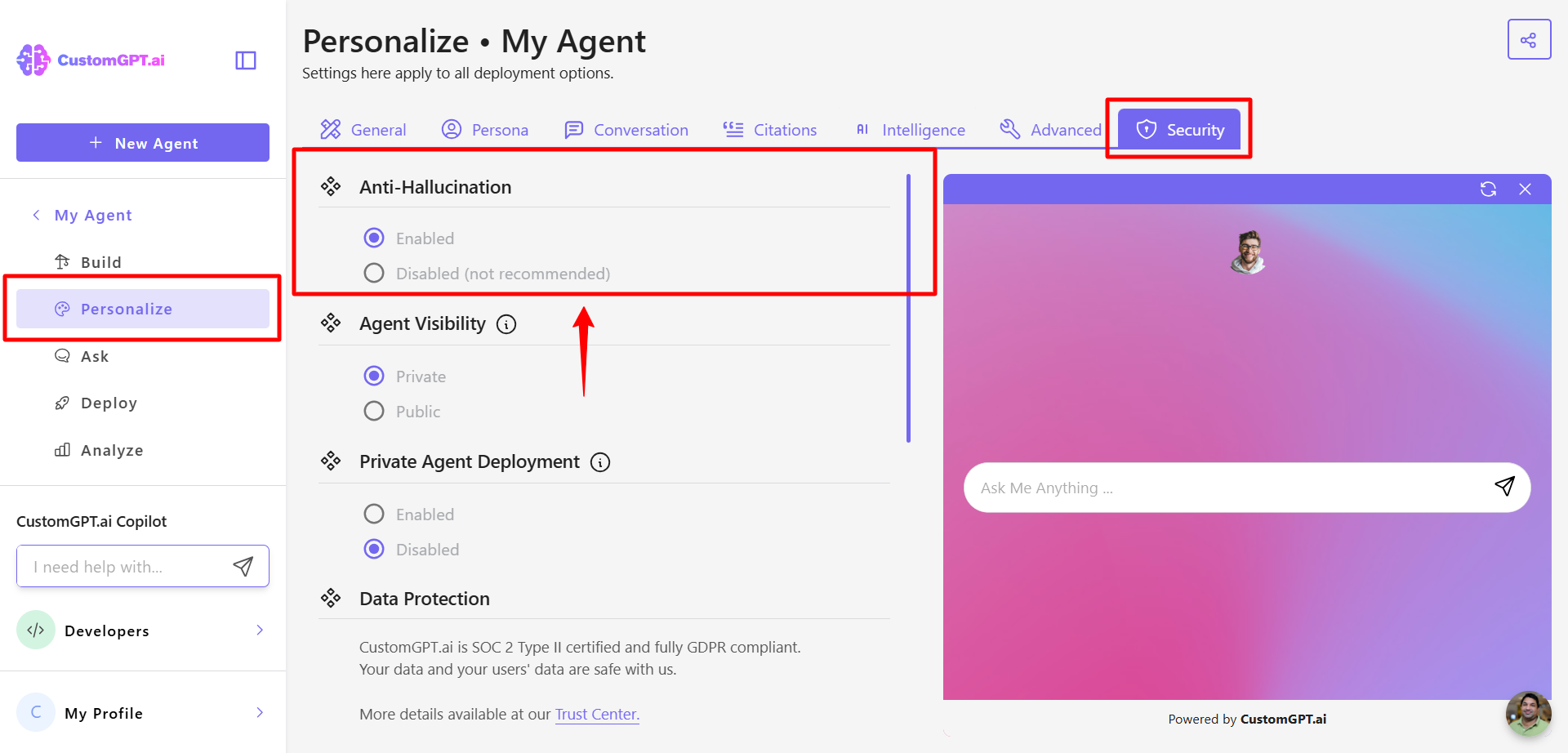
This setting is enabled by default, and it applies CustomGPT.ai’s proprietary prompting techniques that reduce hallucinations and defend against prompt tampering. Keep this setting enabled to ensure your agent maintains response integrity.
- Generate Responses From
Location: Go to your agent’s Personalize > Intelligence tab
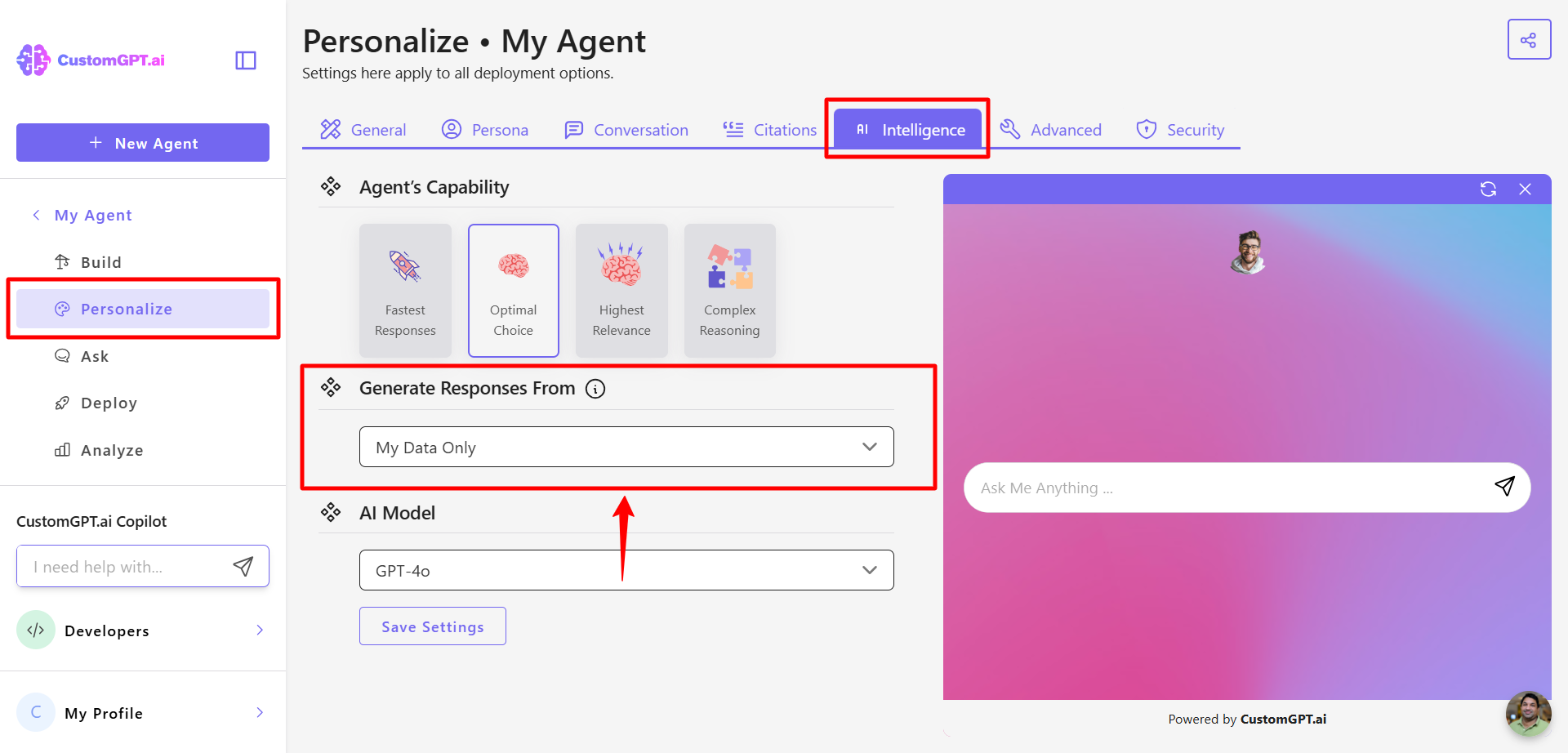
- The default setting is My Data Only, which ensures that your agent responds solely based on the content you’ve uploaded. This dramatically reduces the risk of hallucinations and makes prompt injection much harder to execute.
- You can switch this to My Data + LLM if you want the agent to answer broader or general-purpose queries. However, doing so increases the chance of hallucinations and reduces the effectiveness of your custom Persona.
Warning:Enable My Data + LLM only if you're comfortable trading precision for broader question handling!
📘 Learn more here: Enable agent to use general LLM knowledge
How effective are these defenses?
When the two settings above are left at their default values, agents are protected against over 95% of known prompt injection methods and hallucination risks. These measures work across a wide range of scenarios and are continuously improved by our team.
How we handle new model vulnerabilities
CustomGPT.ai uses the latest OpenAI models under the hood. While rare, major new OpenAI releases may sometimes introduce novel jailbreaks or vulnerabilities. In such cases:
- Our engineering team prioritizes patching vulnerabilities immediately
- You are encouraged to report any suspicious agent behavior to our Customer Support, and we will investigate promptly
To keep your agent secure and accurate:
- Leave Anti-Hallucination enabled
- Keep Generate Responses From set to My Data Only
- Report anomalies immediately for investigation
- Avoid enabling general LLM knowledge unless your use case requires it
These simple best practices ensure your CustomGPT.ai agent remains robust against prompt injection and hallucinations.
Updated 11 months ago