How AI Vision works
This guide explains how AI Vision processes uploaded images to extract meaningful information and add it to your agent’s knowledge base.
What AI Vision does
AI Vision is a feature that processes uploaded images and PDF documents to extract meaningful information and integrate it into an agent's knowledge base. The system uses advanced visual recognition technology to understand image content and create natural-language descriptions.
The technology identifies visual elements within images and generates clear, human-readable summaries. These descriptions are stored in the agent's knowledge base, allowing the agent to reference visual information just like any other data source when providing responses.
For PDF documents, AI Vision works page by page. Each page is processed as a full visual unit. It extracts text that cannot be selected (scanned or image-based content), understands images, diagrams, and charts in context, and reads the page layout as a whole. Each page becomes a knowledge base entry.
What AI Vision can interpret
AI Vision can effectively process:
- Technical diagrams and schematics
- Charts and graphs
- Photographs
- Illustrations
- Handwritten text
- Screenshots
- Product images
- Any other image type
- PDF documents
How AI Vision works for images
- Image upload: You upload one or more images through the file upload modal or when creating a new agent.
- Image processing: The images are processed using OpenAI’s advanced vision models, which analyze the visual content in detail.
- AI analysis and description: The system intelligently interprets what’s in the image such as objects, text, or diagrams, and generates a clear, human-readable summary.
- Knowledge base integration: The generated description is automatically added to your agent’s knowledge base, where it functions as a regular content source.
- Response reference and citations: When your agent uses this information in a response, it can automatically include the image as a citation for context and transparency.
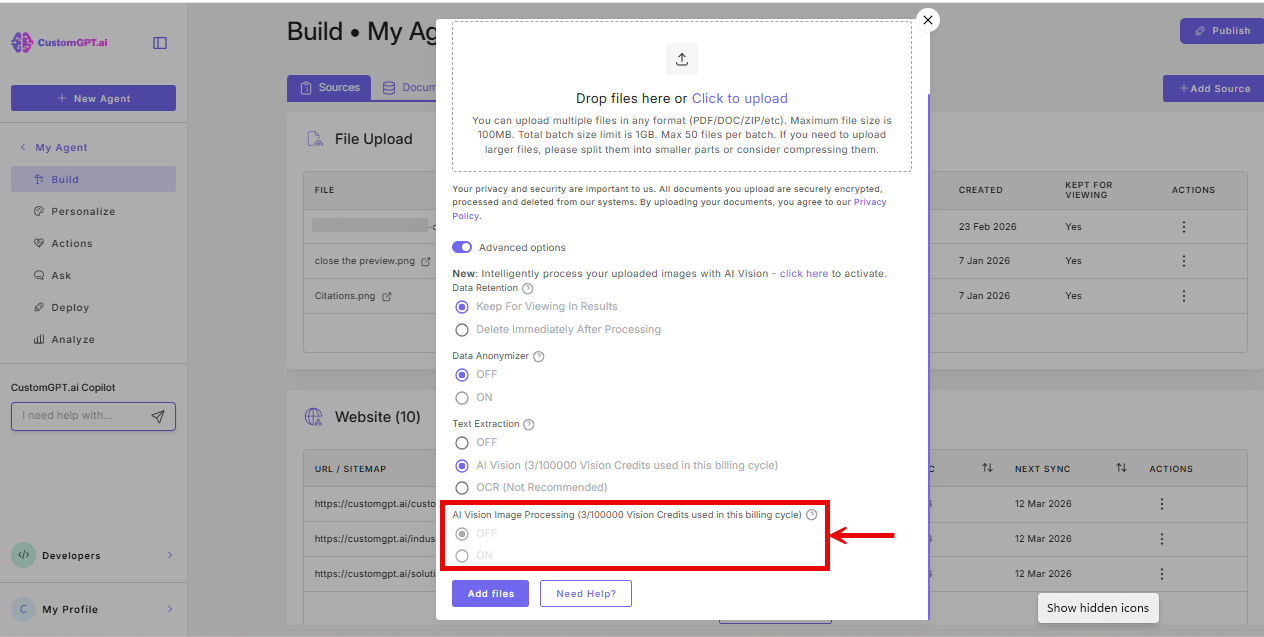
Note:Image citations are automatically enabled for users who have used AI Vision on their agent's knowledge base.
How AI Vision works for PDFs
When you select AI Vision under Text Extraction in the File Upload modal, AI Vision processes your PDF page by page rather than as a single file. For each page:
- Text that cannot be selected- such as scanned or image-based content- is extracted and added to the knowledge base.
- Images, diagrams, and charts on the page are understood in context. The agent can reference and describe them in responses.
- Images are not extracted as separate files. Visual content is understood as part of the page, not stored as individual image sources.
Each page counts as 1 Vision Credit. A 10-page PDF uses 10 Vision Credits.
This is different from how AI Vision works with uploaded images. When processing an image file, the whole image is analyzed as one unit. When processing a PDF, each page is analyzed independently.
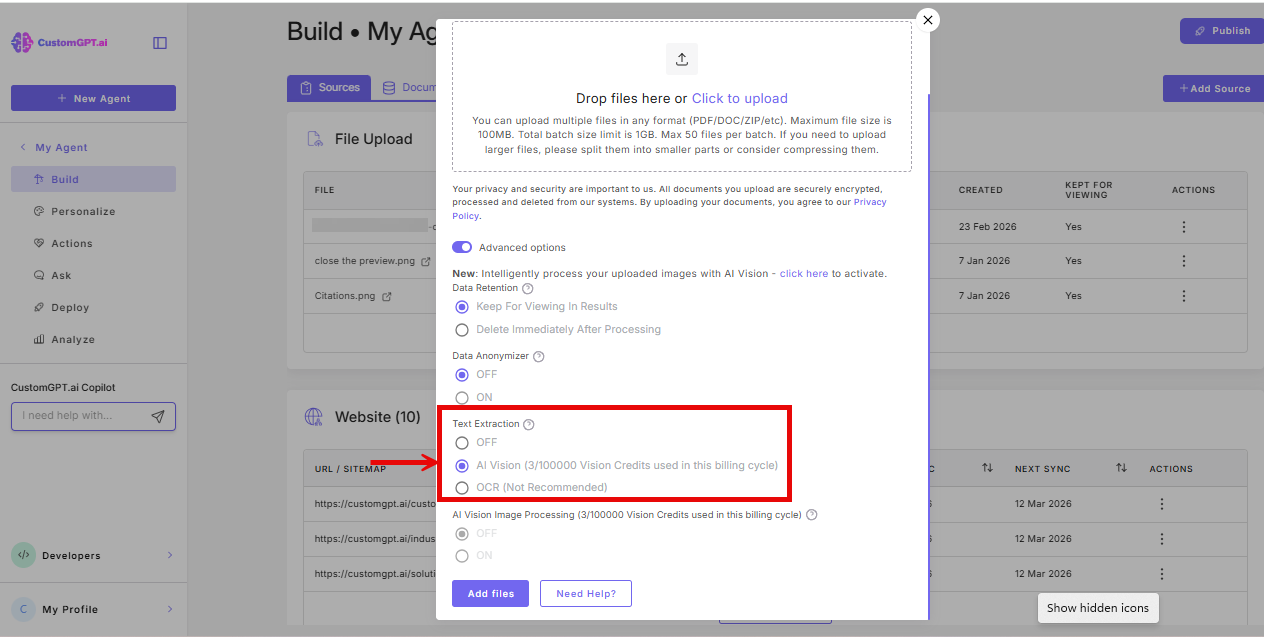
Note: AI Vision PDF text extraction and AI Vision Image Processing cannot be used in the same upload batch. If AI Vision Image Processing is on, the AI Vision option under Text Extraction will be unavailable for that batch. Upload images and PDFs in separate batches to use both.
Related articles:
- Enable AI Vision for uploaded images
- Enable AI Vision for PDF Text Extraction
- Vision processing limits
- Embed your photos in agent responses
- Activate image citations
- How PDF Citations work
- How to configure PDF citations
Updated 4 months ago